

你是否遇到过这样的场景:调用 ChatGPT API 时,用户盯着空白页面等待 10 秒,最后才”唰”地一下显示全部内容?这种体验让用户以为程序”卡死了”——事实上,Python 实现 LLM 流式输出 可以让响应”边生成边显示”,将感知延迟从 10 秒缩短到 0.3 秒。
📌 TL;DR 核心要点
✅ 什么是流式输出:SSE 技术,让 LLM 响应逐 token 返回,而非一次性返回
✅ 为什么要用:用户体验提升 10x,首字节时间从 5-10s 降至 0.2-0.5s
✅ 最简实现:OpenAI SDK stream=True + 迭代器遍历,3 行代码搞定
✅ 生产级方案:FastAPI + SSE + 异步生成器,支持高并发
✅ 常见陷阱:缓冲区阻塞、Token 拼接乱码、连接超时、内存泄漏
✅ 什么是流式输出:SSE 技术,让 LLM 响应逐 token 返回,而非一次性返回
✅ 为什么要用:用户体验提升 10x,首字节时间从 5-10s 降至 0.2-0.5s
✅ 最简实现:OpenAI SDK stream=True + 迭代器遍历,3 行代码搞定
✅ 生产级方案:FastAPI + SSE + 异步生成器,支持高并发
✅ 常见陷阱:缓冲区阻塞、Token 拼接乱码、连接超时、内存泄漏
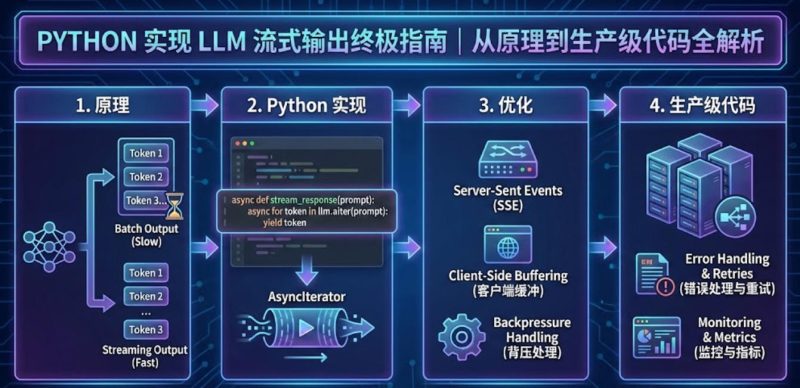
一、什么是 LLM 流式输出?
1.1 传统模式 vs 流式模式
| 对比项 | 传统模式 | 流式模式 |
| 响应方式 | 等待全部生成完毕,一次性返回 | 边生成边返回,逐 token 推送 |
| 首字节时间 (TTFB) | 5-15 秒(取决于内容长度) | 0.2-0.5 秒 |
| 用户体验 | ❌ 长时间空白等待,感觉”卡死” | ✅ 即时反馈,类似真人打字 |
| 技术实现 | 普通 HTTP 请求 | SSE / WebSocket |
1.2 SSE (Server-Sent Events) 协议解析
SSE 是一种基于 HTTP 的服务端推送技术,特点:
- 单向通信:服务端 → 客户端
- 基于文本:每条消息以
data:开头,以\n\n结尾 - 自动重连:浏览器原生支持断线重连
- 轻量级:相比 WebSocket 更简单,无需握手升级
💡 为什么 ChatGPT、Claude、Gemini 都用 SSE?
LLM 场景是典型的单向数据流(服务端 → 客户端),SSE 足够满足需求且更轻量。只有需要双向通信(如实时协作编辑)才需要 WebSocket。
LLM 场景是典型的单向数据流(服务端 → 客户端),SSE 足够满足需求且更轻量。只有需要双向通信(如实时协作编辑)才需要 WebSocket。
1.3 技术选型矩阵
| 方案 | 适用场景 | 复杂度 | 性能 |
| OpenAI SDK 原生 | 快速原型、脚本工具 | ⭐ | 中 |
| LangChain Streaming | 链式调用、Agent | ⭐⭐ | 中 |
| FastAPI + SSE | Web API、生产部署 | ⭐⭐⭐ | 高 |
| WebSocket | 双向通信、实时协作 | ⭐⭐⭐⭐ | 最高 |
二、Python 实现 LLM 流式输出只需3步|小白10分钟上手
⚡ 速效承诺:按照以下 3 步操作,你可以在 10 分钟内让 LLM 输出”像打字机一样”逐字显示!
Step 1: 环境准备 (2分钟)
pip install openai python-dotenv创建 .env 文件配置 API 密钥:
# .env 文件
OPENAI_API_KEY=sk-xxx
OPENAI_BASE_URL=https://api.suxi.ai/v1 # 推荐使用速夕API中转,国内直连Step 2: 最简流式代码 (3分钟)
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL") # 使用 api.suxi.ai 中转
)
# 🔥 核心:stream=True
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": "用Python写一个快速排序"}],
stream=True # 开启流式输出
)
# 逐 token 打印
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)关键点解析:
stream=True:告诉 API 以流式方式返回chunk.choices[0].delta.content:每个 chunk 只包含增量内容flush=True:强制刷新缓冲区,否则内容会等到换行才显示
Step 3: 完整响应收集 (5分钟)
实际项目中,我们通常需要边输出边收集完整响应:
def stream_chat(prompt: str) -> str:
"""流式输出并收集完整响应"""
full_response = ""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}],
stream=True
)
for chunk in response:
content = chunk.choices[0].delta.content or ""
print(content, end="", flush=True) # 实时输出到控制台
full_response += content # 同时收集完整响应
print() # 换行
return full_response
# 使用示例
result = stream_chat("解释什么是递归")
print(f"\n\n完整响应长度: {len(result)} 字符")✅ 恭喜!你已经完成了 Python LLM 流式输出的基础实现!接下来我们看进阶的生产级方案。
三、LangChain + FastAPI 企业级部署方案
3.1 LangChain 流式输出方案
如果你的项目使用 LangChain 框架,流式输出更加简单:
from langchain_openai import ChatOpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = ChatOpenAI(
model="gpt-4-turbo",
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
openai_api_base="https://api.suxi.ai/v1" # 速夕API中转
)
# 自动流式输出到控制台
response = llm.invoke("解释什么是微服务架构")3.2 FastAPI + SSE 生产级架构
🏗️ 架构说明
前端 (React/Vue) → SSE 连接 → FastAPI 网关 → 流式请求 → OpenAI API / 速夕中转 → 逐 Token 返回 → SSE 推送 → 前端实时显示
前端 (React/Vue) → SSE 连接 → FastAPI 网关 → 流式请求 → OpenAI API / 速夕中转 → 逐 Token 返回 → SSE 推送 → 前端实时显示
完整 FastAPI 服务端代码:
from fastapi import FastAPI, Query
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from openai import OpenAI
import os
app = FastAPI(title="LLM 流式输出 API")
# 允许跨域(开发环境)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url="https://api.suxi.ai/v1" # 速夕API中转
)
async def generate_stream(prompt: str):
"""异步生成器 - SSE 格式"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}],
stream=True
)
for chunk in response:
content = chunk.choices[0].delta.content or ""
if content:
# SSE 格式:data: 内容\n\n
yield f"data: {content}\n\n"
yield "data: [DONE]\n\n"
@app.get("/chat/stream")
async def chat_stream(prompt: str = Query(..., description="用户输入的问题")):
"""流式聊天接口"""
return StreamingResponse(
generate_stream(prompt),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
}
)
# 启动命令: uvicorn main:app --reload --host 0.0.0.0 --port 8000前端调用示例 (JavaScript):
const prompt = "用Python写一个快速排序";
const eventSource = new EventSource(`/chat/stream?prompt=${encodeURIComponent(prompt)}`);
const outputDiv = document.getElementById('output');
eventSource.onmessage = (event) => {
if (event.data === '[DONE]') {
eventSource.close();
console.log('流式输出完成');
return;
}
// 实时追加内容
outputDiv.textContent += event.data;
};
eventSource.onerror = (error) => {
console.error('SSE 连接错误:', error);
eventSource.close();
};3.3 高并发优化配置
| 配置项 | 推荐值 | 说明 |
| uvicorn workers | CPU核心数 × 2 | 多进程并发处理 |
| httpx timeout | 120s | 长文本生成需要更长超时 |
| connection pool | 100 | 连接池大小,避免频繁建连 |
| max_retries | 3 | 失败自动重试 |
# 生产环境启动(4个worker进程)
uvicorn main:app --host 0.0.0.0 --port 8000 --workers 4
# 或使用 gunicorn + uvicorn worker
gunicorn main:app -w 4 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000四、90%开发者踩过的5个性能陷阱
⚠️ 警告:以下是我们在生产环境中踩过的真实坑,每个都可能导致你的流式输出”看起来没生效”!
❌ 陷阱 1: 缓冲区阻塞 (最常见!)
| ❌ 错误写法 | ✅ 正确写法 |
print(content) |
print(content, end="", flush=True) |
原因:Python 默认使用行缓冲,不加 flush=True 会等到遇到换行符才输出。结果就是你以为没生效,其实内容在缓冲区里!
❌ 陷阱 2: 中文 Token 拼接乱码
# ❌ 错误:直接拼接可能导致 UTF-8 截断
full_text += chunk.content # 可能出现乱码
# ✅ 正确:使用 buffer 处理不完整的 UTF-8 序列
buffer = b""
for chunk in response:
if chunk.choices[0].delta.content:
buffer += chunk.choices[0].delta.content.encode('utf-8')
try:
text = buffer.decode('utf-8')
print(text, end="", flush=True)
buffer = b""
except UnicodeDecodeError:
continue # 等待下一个 chunk 补全❌ 陷阱 3: 连接超时未处理
import httpx
# ❌ 错误:无超时设置,可能永久阻塞
client = OpenAI()
# ✅ 正确:设置合理超时
client = OpenAI(
timeout=httpx.Timeout(
60.0, # 总超时 60 秒
connect=10.0 # 连接超时 10 秒
)
)❌ 陷阱 4: 流未正确关闭导致内存泄漏
# ✅ 正确:使用 with 语句确保资源释放
with client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}],
stream=True
) as response:
for chunk in response:
process(chunk)
# 自动关闭连接,避免内存泄漏❌ 陷阱 5: 前端未处理 SSE 断连重连
// ✅ 正确:前端必须处理重连逻辑
let eventSource;
function connect(prompt) {
eventSource = new EventSource(`/chat/stream?prompt=${encodeURIComponent(prompt)}`);
eventSource.onmessage = (event) => {
if (event.data === '[DONE]') {
eventSource.close();
return;
}
document.getElementById('output').textContent += event.data;
};
eventSource.onerror = () => {
console.log('连接断开,3秒后重连...');
eventSource.close();
setTimeout(() => connect(prompt), 3000); // 3秒后重连
};
}五、常见问题 FAQ
Q1: 流式输出和普通输出哪个更费 Token?
Token 消耗完全相同。流式输出只是改变了返回方式(分批 vs 一次性),不影响计费。你不会因为使用流式输出而多花一分钱。
Q2: 流式输出能用于 Function Calling 吗?
可以!OpenAI 支持流式 Function Calling,但需要自行拼接
tool_calls 参数。建议使用 LangChain 封装,它已经处理好了这些细节。Q3: 为什么推荐用 api.suxi.ai 中转?
速夕 API 中转站提供:
① 国内高速访问:无需科学上网,延迟低至 50ms
② 统一管理多模型:一个接口调用 GPT-4/Claude/Gemini/国产大模型
③ 成本优化:比官方更实惠
④ 稳定可靠:自动负载均衡和故障切换
① 国内高速访问:无需科学上网,延迟低至 50ms
② 统一管理多模型:一个接口调用 GPT-4/Claude/Gemini/国产大模型
③ 成本优化:比官方更实惠
④ 稳定可靠:自动负载均衡和故障切换
Q4: WebSocket 和 SSE 该怎么选?
SSE 优先。LLM 场景是单向数据流(服务端 → 客户端),SSE 更轻量、实现更简单。只有需要双向通信(如实时协作编辑、多人游戏)才需要 WebSocket。
Q5: 流式输出支持哪些模型?
主流大模型均支持流式输出:
• OpenAI:GPT-4、GPT-4 Turbo、GPT-3.5 Turbo
• Anthropic:Claude 3 Opus/Sonnet/Haiku
• Google:Gemini Pro、Gemini Ultra
• 国产:通义千问、文心一言、智谱 GLM、Moonshot
• 开源:Llama 3、Mistral、Qwen
• OpenAI:GPT-4、GPT-4 Turbo、GPT-3.5 Turbo
• Anthropic:Claude 3 Opus/Sonnet/Haiku
• Google:Gemini Pro、Gemini Ultra
• 国产:通义千问、文心一言、智谱 GLM、Moonshot
• 开源:Llama 3、Mistral、Qwen
Q6: 如何实现”打字机效果”的前端展示?
前端使用
• 原生方案:每收到一个 chunk 就追加到 DOM
• 动画增强:配合 CSS
• 第三方库:使用
EventSource 接收 SSE 数据,配合以下方式实现打字机效果:• 原生方案:每收到一个 chunk 就追加到 DOM
• 动画增强:配合 CSS
animation 添加光标闪烁效果• 第三方库:使用
typed.js 库实现更炫酷的效果六、总结与下一步
核心要点回顾
体验提升 10x
流式输出让首字节时间从 5-10s 降至 0.2-0.5s
3 行代码搞定
stream=True + 迭代器遍历,就是这么简单
生产级方案
FastAPI + SSE + 异步生成器,支持高并发
5 大陷阱
缓冲区、编码、超时、内存泄漏、断连重试
🚀 立即体验企业级 LLM 流式服务
文中所有代码均已适配 速夕 API 中转站 (
⚡ 国内直连,延迟低至 50ms
💰 成本优化,比官方更实惠
🔄 一个接口,统一调用 GPT-4 / Claude / Gemini / 国产大模型
文中所有代码均已适配 速夕 API 中转站 (
api.suxi.ai),提供:⚡ 国内直连,延迟低至 50ms
💰 成本优化,比官方更实惠
🔄 一个接口,统一调用 GPT-4 / Claude / Gemini / 国产大模型
参考资料
📅 最后更新:2025年1月15日 | 版本 v2.0
本次更新:新增 LangChain 0.2 适配、GPT-4 Turbo 流式优化
© 版权声明
分享是一种美德,转载请保留原链接
THE END





请登录后查看评论内容